Материалы по тегу: sambanova systems
|
24.02.2025 [12:22], Сергей Карасёв
SambaNova развернула самую быструю инференс-платформу для ИИ-модели DeepSeek-R1 671BКомпания SambaNova объявила о том, что в её облаке SambaNova Cloud стала доступна большая языковая модель DeepSeek-R1 с 671 млрд параметров. При этом благодаря применению фирменных ускорителей SN40L обеспечивается рекордно высокая скорость инференса. Изделия SambaNova SN40L RDU (Reconfigurable Dataflow Unit) состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM и 64 Гбайт памяти HBM3. Восьмипроцессорная система на базе SN40L, по заявлениям SambaNova, способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256k. Платформа SambaNova Cloud при использовании DeepSeek-R1 671B демонстрирует производительность до 198 токенов в секунду, что на сегодняшний день является рекордным показателем. Для сравнения: у ближайшего конкурента — Together AI — результат составляет 98 токенов в секунду, а у Microsoft Azure — 20 токенов в секунду. Ранее Cerebras объявила о собственном рекорде — до 1508 токенов/с, но для гораздо более скромной и, по мнению компании, практичной модели DeepSeek-R1-Distill-Llama-70B. 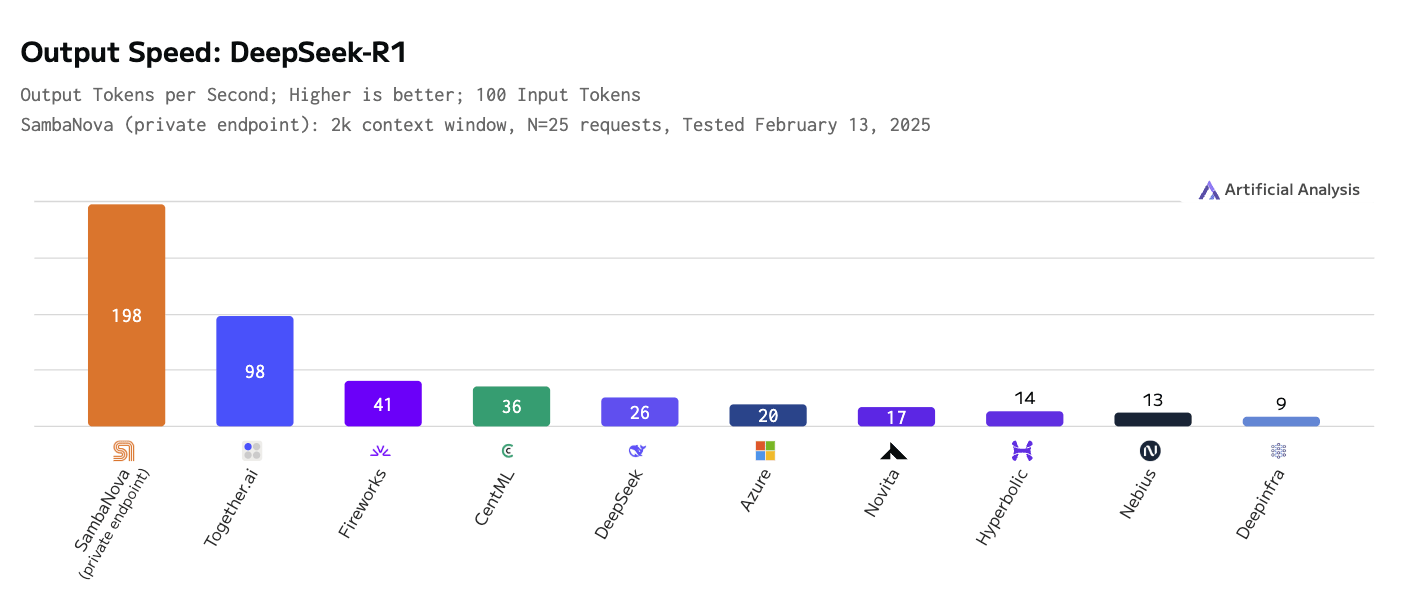
Источник изображения: SambaNova Утверждается, что ускорители SambaNova SN40L RDU по сравнению с новейшими GPU обеспечивают в три раза большую производительность и в пять раз более высокую эффективность. В частности, по заявлениям SambaNova, одна стойка с 16 экземплярами SN40L RDU по быстродействию сопоставима с 40 стойками, насчитывающими в общей сложности 320 передовых GPU. Таким образом, существенно сокращаются затраты на использование DeepSeek-R1 671B. Доступ к DeepSeek-R1 671B в облаке SambaNova Cloud предоставляется посредством API. В перспективе компания планирует наращивать вычислительные мощности, обеспечив производительность на уровне 20 000 токенов в секунду.
11.09.2024 [18:07], Сергей Карасёв
SambaNova запустила «самую быструю в мире» облачную платформу для ИИ-инференсаКомпания SambaNova Systems объявила о запуске облачного сервиса SambaNova Cloud: утверждается, что на сегодняшний день это самая быстрая в мире платформа для ИИ-инференса. Она ориентирована на работу с большими языковыми моделями Llama 3.1 405B и Llama 3.1 70B, насчитывающими соответственно 405 и 70 млрд параметров. В основу сервиса положены ИИ-чипы собственной разработки SN40L. Эти изделия состоят из двух крупных чиплетов, оперирующих 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной памяти HBM3. Утверждается, что восьмипроцессорная система на базе SN40L способна запускать и обслуживать ИИ-модели с 5 трлн параметров и глубиной запроса более 256к. 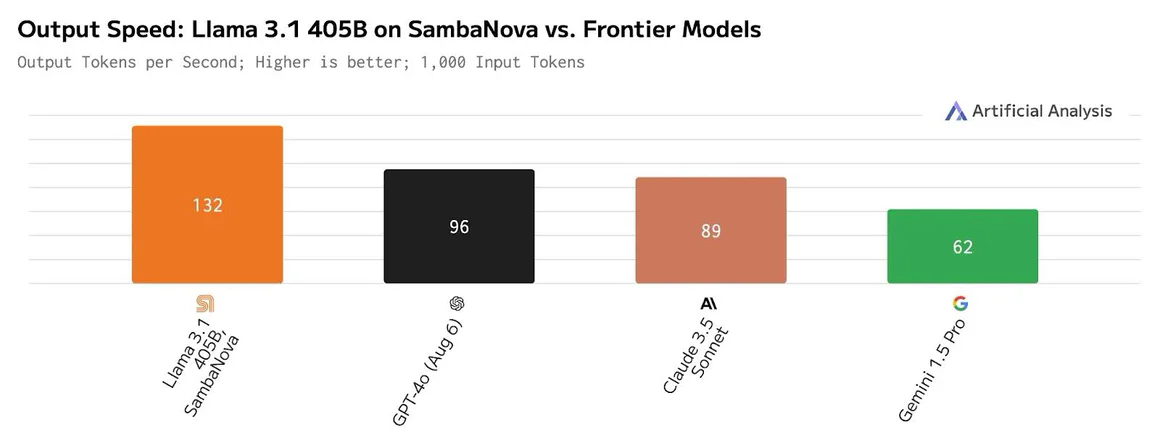
Источник изображения: SambaNova Платформа SambaNova Cloud, по заявлениям разработчиков, демонстрирует производительность до 132 токенов в секунду при работе с Llama 3.1 405B и до 461 токена в секунду при использовании Llama 3.1 70B. Для сравнения, по оценкам Artificial Analysis, даже самые мощные системы на базе GPU могут обслуживать модель Llama 3.1 405B только со скоростью 72 токена в секунду, а большинство из них намного медленнее. Подчёркивается, что SambaNova Cloud демонстрирует рекордную скорость при сохранении полной 16-битной точности. Однако без компромиссов всё же не обошлось: модель работает не в полном контекстном окне в 128k, а при 8k. Доступ к SambaNova Cloud предоставляется по трём схемам — Free, Developer и Enterprise. Первая предусматривает бесплатное базовое использование через API. Схема для разработчиков Developer (появится к концу 2024 года) позволяет работать с моделями Llama 3.1 8B, 70B и 405B с более высокими лимитами. Наконец, план Enterprise предлагает корпоративным клиентам возможность масштабирования для поддержки ресурсоёмких рабочих нагрузок. Ранее Cerebras Systems тоже объявила о запуске «самой мощной в мире» ИИ-платформы для инференса, а Groq ещё в прошлом году говорила о преимуществах своих решений и тоже переключилась на создание облачных сервисов. Впрочем, в бенчмарках MLPerf Inference по-прежнему бессменно лидируют решения NVIDIA.
29.02.2024 [13:01], Владимир Мироненко
ИИ-консилиум: корпоративная LLM Samba-1 c 1 трлн параметров объединила более 50 открытых моделейСтартап SambaNova Systems представил Samba-1, модель генеративного ИИ с 1 трлн параметров, предназначенную для использования предприятиями. SambaNova описывает новую модель как «объединение экспертных архитектур» (Composition of Experts, CoE), которое включает более 50 открытых моделей генеративного ИИ высочайшего качества, в том числе Llama2 7B/13B/70B, Mistral 7B, DeepSeek Coder 1.3B/6.7B/33B, Falcon 40B, DePlot, CLIP, Llava. В частности, Llama 2 может генерировать текст, создавать программный код и решать математические задачи. Есть и более специализированные LLM, такие как DePlot от Google, которая может вводить информацию из диаграмм и других визуализаций данных в электронную таблицу. Samba-1 уже используется клиентами и партнёрами SambaNova, включая Accenture и NetApp. 
Источник изображений: SambaNova SambaNova позиционирует Samba-1 как первую модель с 1 трлн параметров для предприятий с регулируемой деятельностью, которая является приватной, безопасной и на порядок более эффективной, чем любая другая модель такого размера. Заказчик может установить контроль доступа к данным для отдельных пользователей. Желающие могут ознакомиться с работой модели. По словам главы SambaNova, Samba-1 оптимизирована для работы с чипом SN40L, выпущенным стартапом прошлой осенью. «Samba-1 способна конкурировать с GPT-4, но она лучше подходит для предприятий, поскольку её можно развернуть как локально, так и в частном облаке, чтобы клиенты могли точно настроить модель с использованием своих личных данных, не отдавая их в открытый доступ», — добавил он. 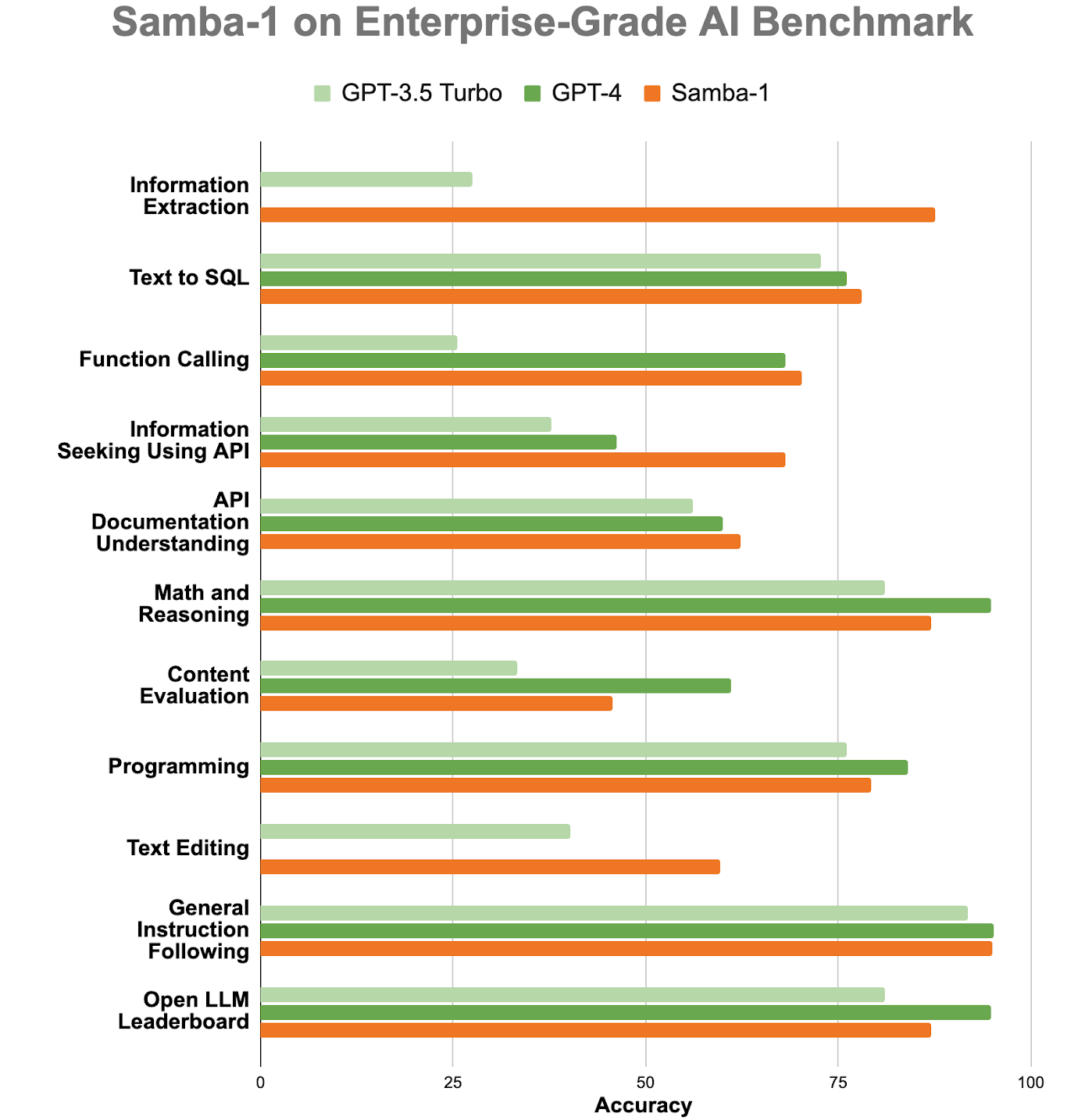 SambaNova утверждает, что инференс этой модели обходится в десять раз дешевле, чем для конкурирующих LLM. Получив запрос, Samba-1 решает, какая из её внутренних моделей лучше всего приспособлена для его обработки, и поручает ей сгенерировать ответ. То есть активируется только одна из относительно небольших моделей, тогда как традиционные монолитные LLM требуют активации целиком. Стартап SambaNova привлёк около $1 млрд инвестиций от ряда компаний, включая Intel Capital и GV (инвестиционное подразделение Alphabet Inc). По итогам раунда финансирования в начале 2021 года рыночная стоимость стартапа оценивается в более чем $5 млрд.
24.11.2023 [17:14], Сергей Карасёв
Лос-Аламосская национальная лаборатория внедрит обновлённые ИИ-системы SambaNovaЛос-Аламосская национальная лаборатория (LANL) Министерства энергетики США (DOE) заключила соглашение о сотрудничестве со стартапом SambaNova Systems, который специализируется на разработке ИИ-решений. Финансовые условия договора не раскрываются, но ранее стартап уже поставлял LANL свои решения. В рамках партнёрства LANL расширит применение программно-аппаратных комплексов SambaNova DataScale. Речь идёт о системе DataScale SN30, содержащей восемь ускорителей собственной разработки Cardinal SN30, суммарно имеющих 5 Гбайт SRAM и 8 Тбайт DRAM. Конфигурация комплекса может включать от одного до трёх узлов SN30. Кроме того, LANL внедрит решение SambaNova Suite для генеративного ИИ. Эта платформа предоставляет различные ИИ-модели, оптимизированные для корпоративных и государственных организаций. Они могут быть развёрнуты локально или в облаке с возможностью адаптации к собственному набору данных заказчика. 
Источник изображения: SambaNova Новое многолетнее соглашение между LANL и SambaNova является расширением действующего партнёрства между сторонами. Лаборатория будет использовать технологии SambaNova для решения широкого спектра задач, связанных с ИИ и большими языковыми моделями (LLM), в том числе в интересах национальной безопасности. Отмечается, что платформа SambaNova Suite предлагает быстрый и эффективный способ развёртывания генеративного ИИ для реализации самых сложных проектов.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 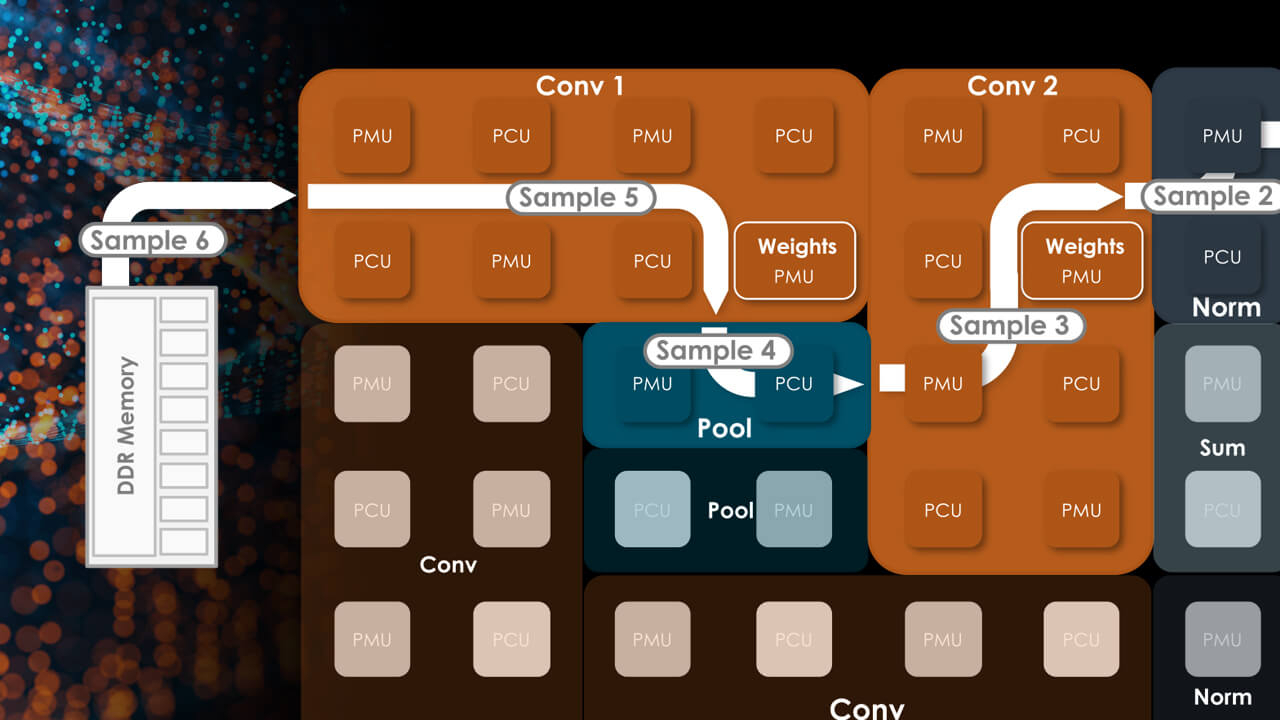
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
16.09.2022 [22:58], Алексей Степин
SambaNova Systems представила второе поколение ИИ-систем DataScale — SN30 с 5 Гбайт SRAM и 8 Тбайт DRAMСтартап SambaNova, решивший бросить вызов NVIDIA, представил второе поколение систем машинного обучения — DataScale SN30. В основе лежит собственная разработка компании, ускоритель Cardinal SN30, для обозначения которого SambaNova использует термин Reconfigurable Data Flow Unit (RDU). На новинку уже обратили внимание такие организации, как Аргоннская национальная лаборатория (ANL) и Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL). Cardinal SN30 состоит из 86 млрд транзисторов и производится с использованием 7-нм техпроцесса TSMC. Главной его особенностью является возможность реконфигурации: создатели уподобляют этот процессор сложным FPGA. Последним он уступает в степени гибкости, поскольку не может менять конфигурацию на уровне отдельных логических вентилей, зато выигрывает в скорости перепрограммирования и уровне энергопотребления. За это отвечает фирменный программный стек. 
Источник: HPCwire Большой упор SambaNova сделала на объёме локальной памяти, поскольку современные модели машинного обучения имеют тенденцию к гигантомании. Только SRAM-кеша у Cardinal SN30 640 Мбайт, а объём DRAM составляет 1 Тбайт. По своим параметрам SN30 вдвое превосходит чип первого поколения, SN10, но имеет такую же тайловую архитектуру с программным управлением. 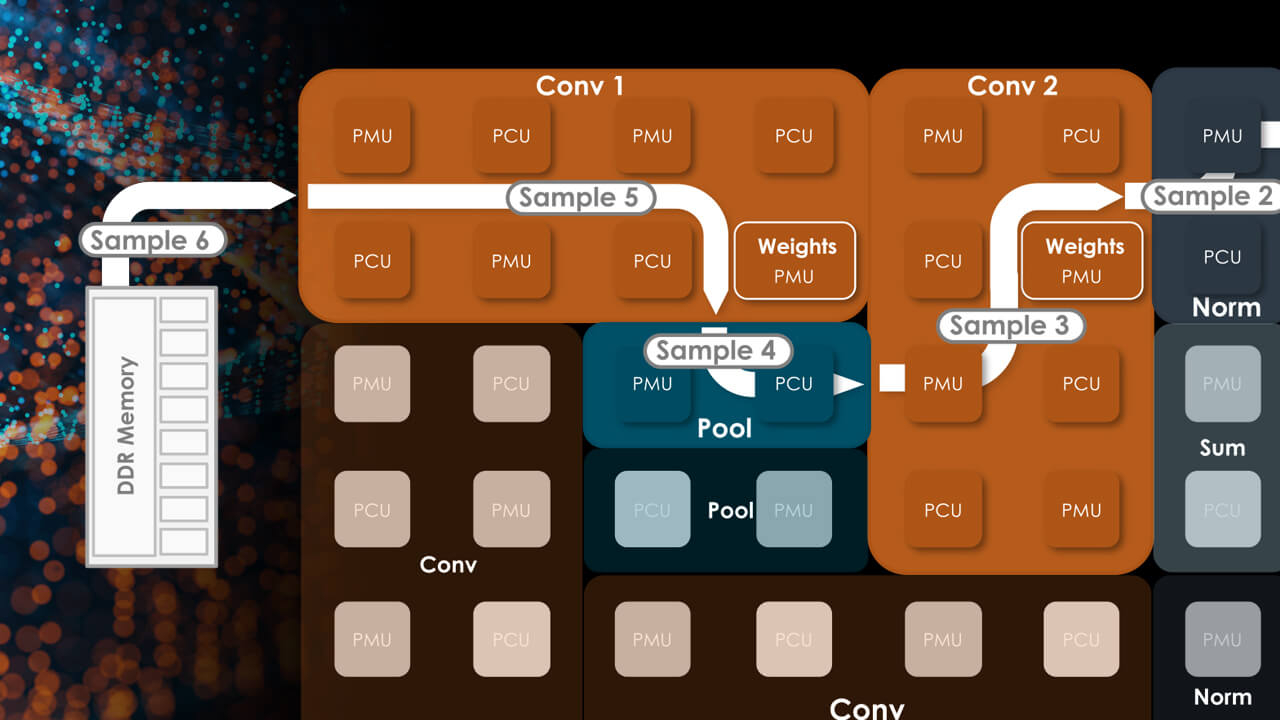
Здесь и далее источник изображений: SambaNova Каждый тайл содержит блоки PCU, отвечающие за вычисления, блоки PMU, содержащие SRAM и обслуживающую логику, а также mesh-интерконнект, обслуживаемый блоками коммутаторов. Такой подход к построению процессора весьма напоминает Tesla D1, у которых вычислительные блоки похожим образом чередуются с блоками быстрой SRAM-памяти. Отдельно ускорители компания не поставляет, минимальная конфигурация готовой 42U-системы DataScale включает в себя 8 чипов SN30.  Комплектация может включать в себя от одного до трёх узлов SN30. Воспользоваться возможностями DataScale можно и в виде услуги, поскольку новинка легко интегрируется в облачные среды и полностью поддерживает платформу Kubernetes. Полный список провайдеров ещё уточняется, на сегодняшний момент партнерами SambaNova являются Aicadium, Cirrascale и ORock.  Высокая производительность в режиме BF16 является главным достоинством новинки — по словам вице-президента SambaNova, каждый чип развивает 688 Тфлопс. Это более чем вдвое выше показателя A100, составляющего 312 Тфлопс. По словам компании, DataScale SN30 вшестеро производительнее NVIDIA DGX A100 (40 Гбайт) и эффективнее всего проявляет себя при обучении сверхбольших моделей вроде GPT-3 с её 13 млрд параметров. Однако нельзя не отметить, что, во-первых, сравнение идёт со старым продуктом NVIDIA, которая вот-вот представит DGX H100, а во-вторых, SambaNova не упоминает в явном виде энергопотребление одного узла SN30. |
|

